Load Balancing Requests Across Proxy Pools: A Practical Guide

Your jobs are slow, block rates are rising, and a few overworked IPs are doing all the lifting. That’s a proxy problem and an allocation problem. With smart proxy load balancing, you can spread traffic across pools, lower bans, and improve data quality. By the end, you’ll know how to design, tune, and monitor a resilient proxy layer.
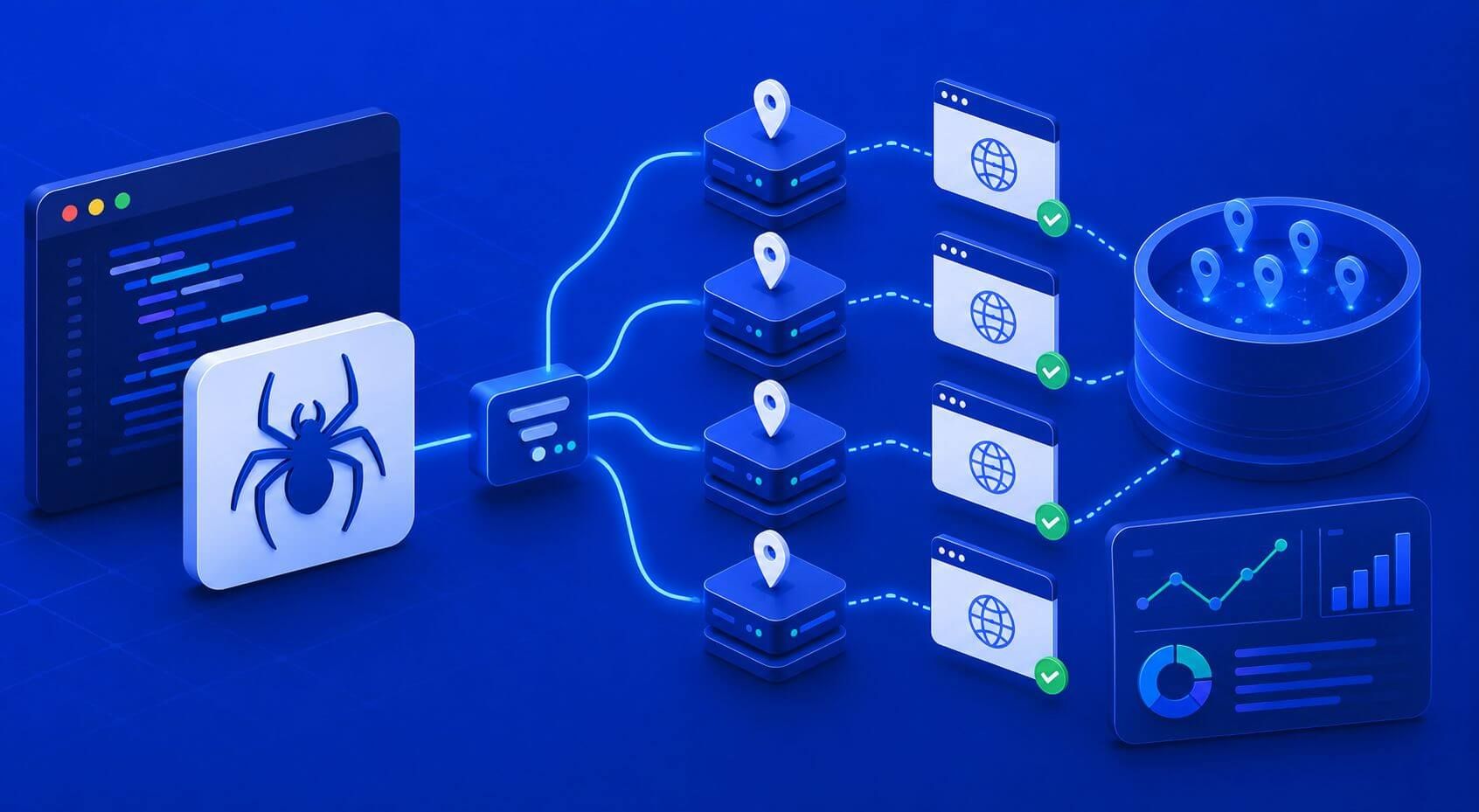
Proxy load balancing distributes requests across multiple proxies so no single IP or subnet gets overused. The goal is to reduce blocks and latency while keeping session stability and geo accuracy. In practice, you’ll blend routing methods, health checks, and rate controls per target to match each site’s defenses.
Why balancing proxy pools changes outcomes
Balancing is about more than speed. It’s about survival, cost, and predictability.
- Operations: Even spread cuts the risk of bans and rate limits. Stable sessions mean fewer retries and re-crawls.
- Finance: You pay per IP, GB, or request. Waste shows up as high cost per successful request (CPSR). Better routing trims CPSR and cloud runtime.
- Data quality: Consistent coverage yields cleaner panels, better price and inventory deltas, and fewer gaps.
If you’re new to the landscape, this comprehensive proxy guide covers the building blocks you’ll route across.
Proxy types change how you balance
Not all pools behave the same under pressure.
- Datacenter pools: Fast and cheap, but easier to flag. Use strict per-domain caps and rotate more often. See how this class behaves here: datacenter proxies.
- Residential or ISP pools: Higher trust and broader ASN mix. Costlier and sometimes slower. Favor session pinning and lower per-IP concurrency. Learn more in this overview of residential proxies.
Match pool to target. For static pages, datacenter often wins on cost. For logged-in flows or anti-bot WAFs, residential or ISP is safer. Your balancer should reflect those tradeoffs.
How to do proxy load balancing in production
Start simple and layer in intelligence only where it pays off.
- Round-robin as a baseline
- What it is: Cycle through IPs evenly.
- Why it helps: Quick to implement and prevents hot-spotting.
- Add-on: Cap per-IP concurrency (example target to validate in a pilot: 1–3 concurrent requests per IP for strict targets).
- Weighted round-robin
- What it is: Give more traffic to healthier or cheaper pools.
- Why it helps: Pools differ in speed, reliability, and price. Weights reflect that.
- How to set weights: Use recent success rate and latency percentiles. Recompute every few minutes.
- Least-connections / in-flight-aware
- What it is: Send the next request to the proxy with the fewest active requests.
- Why it helps: Smooths bursts and reduces queueing delay.
- Caveat: Needs accurate, timely in-flight counters.
- Consistent hashing (session affinity)
- What it is: Map a key (account, cookie jar, or product ID) to the same proxy over time.
- Why it helps: Preserves identity for logins and carts, and reduces suspicious context switches.
- Tip: Use a ring with virtual nodes so you can add/remove proxies with minimal churn.
- Health and error-aware routing
- What it is: Penalize IPs with rising 403/429s, captchas, or high connect time.
- Why it helps: Bad actors cool off while healthy IPs carry more load.
- Reset: Let penalized IPs recover after a backoff window.
Architecture patterns that scale
- Client-side balancer: Your scraper/worker selects proxies directly. Simple and low-latency, but harder to coordinate across many workers.
- Gateway balancer: A central proxy gateway routes traffic to pools. Easier to manage quotas, health, and geo; adds one hop of latency.
- Queue + rate control: Put tasks in queues keyed by domain or risk level. Apply per-queue QPS limits and per-IP caps.
A blended approach works well: gateway for policy and health; client hints for session keys and desired geos.
Routing rules to match site defenses
Most targets fall into three buckets. Tune rules per bucket.
- Static/low-risk content: Round-robin or least-connections. Prefer cheaper pools. Lower session stickiness.
- Moderate defenses: Weighted round-robin with error-aware damping. Keep small sessions (3–10 requests per IP). Cap QPS per subnet.
- High friction (logins, carts, dynamic pages): Consistent hashing to maintain identity. Small per-IP concurrency. Aggressive retry with backoff across fresh IPs.
For ideas on where this matters in the real world, browse common proxy use cases.
A small decision aid
| Method | Best for | Signals to watch |
|---|---|---|
| Round-robin | Large, uniform pools; static pages | Even IP usage, 2xx/3xx mix, rising 429s |
| Weighted RR | Mixed pools with cost/quality gaps | Pool success rate, P95 latency, CPSR |
| Least-connections | Bursty jobs; API polling | Queue depth, in-flight per IP |
| Consistent hashing | Logins, carts, account-bound flows | Session survival rate, cookie errors |
| Error-aware | Unstable targets; WAF pressure | 403/429 spikes, captcha rate |
In plain terms: pick the simplest method that keeps blocks low and latency stable, then add weights or affinity only when you see specific pain.
Implementation blueprint
- Inventory your pools and constraints
- For each pool, track max QPS, cost units (GB/request), subnet diversity, and typical block patterns.
- Build a policy layer
- Define per-domain rules: method, per-IP concurrency, session length, retry/backoff.
- Example: site A uses weighted RR with 70% datacenter, 30% residential, 2 req/IP, 5-request sessions.
- Add health checks and feedback
- Track rolling success rate, connect errors, P95 latency, and captcha hits per IP and pool.
- Demote bad actors with exponential backoff; promote recovering IPs gradually.
- Rate-limit by target and identity
- Cap QPS per domain and per IP/subnet.
- For authenticated flows, hash by account or cookie jar to preserve continuity.
- Logging and traceability
- Log proxy ID (hashed), pool, region, and outcome per request.
- Sample HTML for blocked and successful pages to debug fingerprint issues.
- Safe rollout
- Start with 5–10% of traffic on new policies.
- Compare CPSR, block rate, P95 latency, and success rate before/after.
Two real-world scenarios
Price monitoring at scale: 2 million daily product pages, mostly static. Weighted round-robin sends 80% to datacenter and 20% to residential for stubborn categories. Per-IP concurrency limited to 2. Result: lower blocks and 20–30% faster runtimes in a pilot, with CPSR trending down.
Travel search with logins: Requires stable sessions and region-specific fares. Consistent hashing by account ID, small sessions (5–8 requests), and error-aware damping. Residential IPs for checkout steps only. Outcome: fewer forced logouts and better cart completion during peak hours.
Monitoring that actually reduces risk
Track what moves the needle and wire alerts to thresholds you can act on.
- Block rate: Share of 403/429/timeouts. Alert on spikes by domain and pool.
- Success rate: 2xx/3xx share. Pair with HTML sampling to catch soft blocks.
- Latency: P50/P95. Report by pool and by route rule.
- Captcha rate: Rising captchas are an early warning.
- Geo accuracy: Match IP geo to target needs. Alert on drift.
- Session stability: Median requests per session before failure.
- Cost per successful request (CPSR): Roll up network and compute.
Watch out for this
- Over-sticky sessions: Long sessions look human but can concentrate risk. Keep them short unless you must keep identity.
- Ignoring subnets: Sites often flag at the subnet level. Spread traffic across CIDRs, not just unique IPs.
- One-size-fits-all rules: Every domain’s defenses differ. Use per-domain policies.
- Blind rotations: Rotating too fast can look automated. Vary intervals and session lengths.
- Unlabeled retries: Tag retries so they don’t stampede the same IPs.
Tuning playbook
- Pilot thresholds: Validate per-IP concurrency at 1, 2, and 3 on strict targets. Compare block rate and CPSR.
- Weight learning: Recompute weights from last 5–15 minutes of outcomes. Smooth changes to avoid flapping.
- Backoff math: Multiply cool-down windows on repeated errors, then decay slowly.
- Fingerprint hygiene: Align browser headers and TLS hints with your pool type. Small mismatches can cause silent blocks.
Compliance and governance
Keep a short, written policy by use case and region. Control target allow-lists, data retention, and PII handling. Enforce robots and terms where required. Log purpose and legal basis for regulated markets. Good governance reduces brand and legal risk while keeping teams aligned.
Frequently Asked Questions
How many proxies do I need per domain?
This depends on target defenses and desired QPS. Start from your required throughput, then cap per-IP concurrency (example pilot: 1–3 for strict targets, 3–5 for lenient). Increase pool size until block rate and latency stabilize without pushing CPSR up.
Should I balance across datacenter and residential pools together?
Yes, but with intent. Use weighted routing to prefer cheaper datacenter IPs for static pages and shift to residential for protected flows. Keep separate per-pool caps, since their block patterns and costs differ.
What signals should drive weights in weighted round-robin?
Use recent success rate, captcha rate, and P95 latency. Include a light cost factor if pools are billed differently. Recompute every few minutes and apply smoothing so short spikes don’t cause large swings.
How do I keep sessions stable without concentrating risk?
Use consistent hashing for accounts or carts, but limit session length. For example, 5–10 requests or 1–3 minutes per session, then rotate. Carry over critical cookies if needed and avoid reusing the same subnet immediately.
Why am I seeing 429s even with many proxies?
Likely hot-spotting at subnet or ASN level, or your per-domain QPS is too high. Add per-subnet caps, slow down bursts, and switch to error-aware routing. Sample HTML on 200s to catch soft blocks masquerading as success.
How can I measure ROI of better balancing?
Track CPSR, completion time per job, and re-crawl rate due to blocks. A good rollout reduces CPSR and runtime while keeping coverage flat or better. Compare baselines to 2–4 week post-change windows.
Is a gateway balancer required?
Not required, but helpful at scale. A gateway centralizes health, quotas, and per-domain policy, which reduces coordination work in client code. If latency is critical, use a lightweight gateway and keep connections warm.
Do I need residential IPs for all targets?
No. Use them where trust and identity matter most—logins, carts, and sensitive APIs. For bulk, anonymous pages, tuned datacenter routing usually wins on cost and speed.
Where to go from here
Effective proxy load balancing blends simple methods with the right feedback loops. The core tradeoffs are session stability vs. spread, and cost vs. trust. Start with round-robin, add weights and error-awareness, and reserve affinity for flows that need identity.
Next steps:
- Define per-domain policies with per-IP caps and session limits.
- Instrument success rate, block rate, P95 latency, captcha rate, geo accuracy, and CPSR.
- Pilot weighted and error-aware routing on 10% of traffic and compare outcomes.
Want to go deeper on patterns and pool selection? Explore SquidProxies resources, including guides on proxy types and operations.
By making proxy load balancing a first-class part of your pipeline, you’ll ship faster, spend smarter, and collect cleaner data—without brittle, hand-tuned scripts.
About the author
Marcus Delgado
Marcus Delgado is a network security analyst focused on proxy protocols, authentication models, and traffic anonymization. He researches secure proxy deployment patterns and risk mitigation strategies for enterprise environments. At SquidProxies, he writes about SOCKS5 vs HTTP proxies, authentication security, and responsible proxy usage.